Reorganising my encrypted partitions and backups
These notes give a high-level overview of some work I did to restructure how I was backing up data at home. YMMV - these aren't optimal decisions and the tools I'm using here will result in data loss if used incorrectly, so always be careful if you're doing anything similar.
1. My setup
My main home machine is a Thinkpad T450s running Arch. It has a single disk. The vast majority of my user data (around 1TB) is stored on one partition encrypted using LUKS, and for a few years I've been using Duplicity to make two separate backups of this data - one to S3, and one to a local disk.
This has worked OK so far, but if I ever need to make another full (ie. non-incremental) backup with Duplicity it's extremely slow, and I suspected that some of this data didn't actually need to be in an incremental backup system because either (1) it wasn't going to change again, or (2) I didn't actually need it in the first place. So I wanted to check what data I had and make some changes.
Analysing disk usage with duc
There are lots of tools that let you analyse disk usage, but I particularly like
duc, as you can run duc index to build up the database and then query separately
it without having to wait. The interactive visualisations provided by duc gui
also look nice:
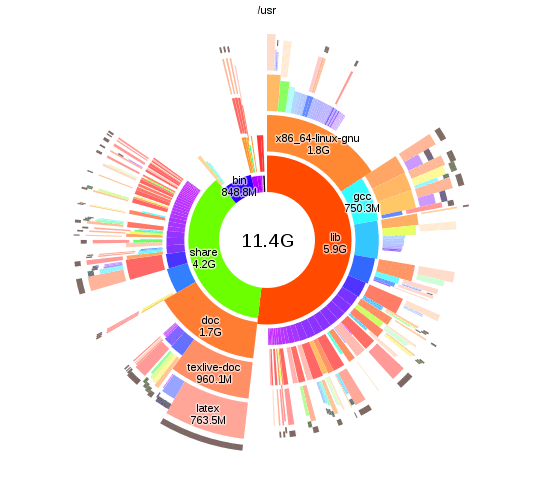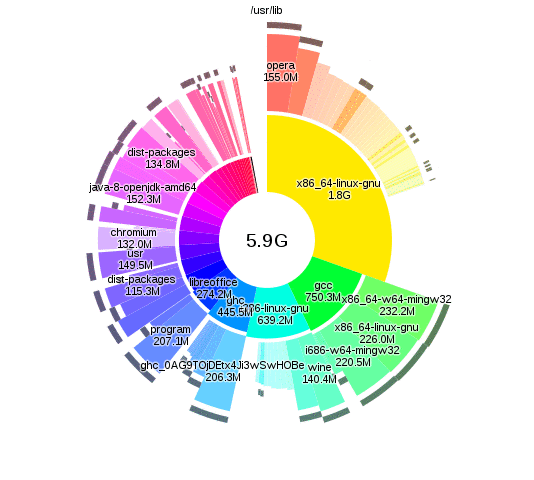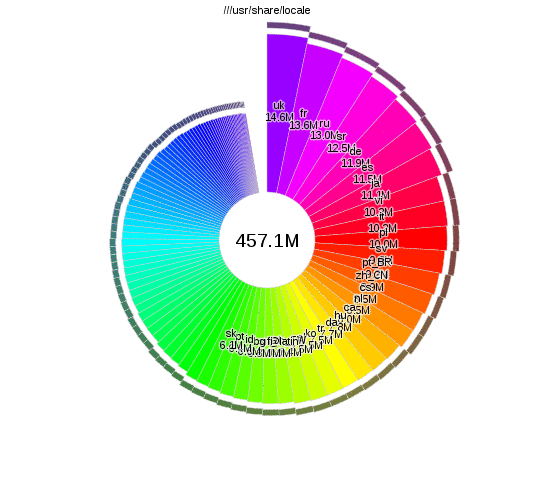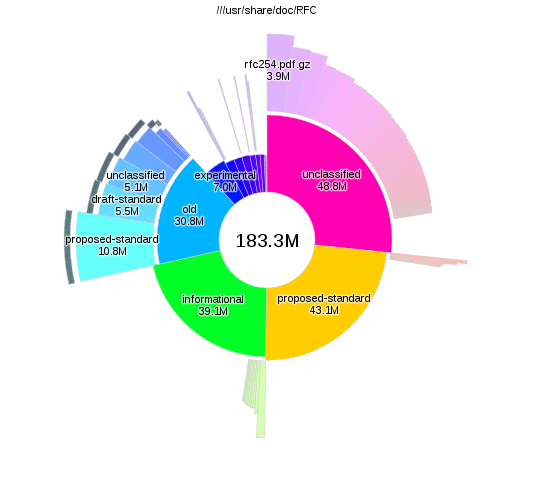
The changes
From the duc results I found some data that I was happy to delete. More significantly though, I realised that I only actually had a few GB of active working files, and hundreds of gigs of old files that I'm not going to change again. The storage and usage requirements of these files was different enough that it didn't make sense to use the same backup system for both.
So the plan was:
- Split my main data partition into two. Move the old files that aren't going to change to a new encrypted partition and mount it as readonly.
- Take some one-off backups of this "readonly" partition.
- Ensure my future Duplicity backups ignore this readonly data.
- While I'm here, securely delete the data on some old hard drives that I have lying around - as I've been putting this off for ages.
2. Resizing a LUKS-encrypted partition with gparted
I had to decrease the size of my main data partition to make space on the disk for the new "readonly" partition. At first my web-searching led to this Arch wiki page on resizing LVM on LUKS. I thought this might be applicable, but I'm not actually using LVM (see Logical Volume Management for background on what LVM is - it basically provides virtual partitions that exist as an abstraction separately from the physical partitions on disk).
All I really needed to do was to decrease the partition size in a way that was compatible with the LUKS encrypted volume. It turns out that gparted does all of this for you.
You first have to make sure the encrypted partition is decrypted, so that gparted can see that it's not full (otherwise it will prevent you from decreasing the partition size):
$ export EXAMPLE_DEVICE=/dev/sdb1 $ cryptsetup open $EXAMPLE_DEVICE mydevice
From there the "resize" feature in gparted just works. If you look at the logs it produces you can see what operations it applies, which are:
- Decrease the partition size.
e2fsck -f -y -v -C 0 $EXAMPLE_DEVICE- check the filesystem on the decreased partition.resize2fs -p /dev/mapper/mydevice 1044475904K- resize the filesystem.cryptsetup -v --size 2088951808 resize 'mydevice'- resize the LUKS volume (if you were doing this manually this step wouldn't necessarily be required - LUKS calculates the volume size automatically whenever the volume is decrypted, so the resize command is only useful for a "live" resize).
3. Creating a new partition with cryptsetup
Once the main partition had been shrunk, I could use gparted to create a new partition in the now-unallocated space.
To set up the new LUKS volume, you can use cryptsetup:
$ export MY_NEW_PARTITION=/dev/sda6 $ cryptsetup luksFormat -y -v --type luks2 $MY_NEW_PARTITION
This sets up the encrypted volume, prompting you for a passphrase.
You can then use cryptsetup open $MY_NEW_PARTITION mynewpartition, and it will
appear as /dev/mapper/mynewpartition.
With the volume decrypted, you then need to create a filesystem:
$ mkfs.ext4 /dev/mapper/mynewpartition mke2fs 1.46.4 (18-Aug-2021) Creating filesystem with 2555904 4k blocks and 638976 inodes Filesystem UUID: 2ea513e3-4cd2-479e-9ac2-1288cb99eb22 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
You can then mount this to confirm it works:
$ mkdir /mnt/test $ mount /dev/mapper/mynewpartition /mnt/test
With this mounted, I could move the desired files onto the new partition.
4. Mounting the partition as readonly in fstab
By default Arch uses systemd-boot. Assuming that you've got the sd-encrypt hook
configured in /etc/mkinitcpio.conf, you can configure the boot loader to decrypt
a volume on startup by editing /boot/loader/entries/$myfile.conf (for non-root
partitions you can also configure /etc/crypttab, but as my root
partition is encrypted I need to do that one here anyway, and so for consistency
I've got the other partitions configured here too).
For me the boot loader config looks something like this:
$ cat /boot/loader/entries/arch.conf title Arch Linux machine-id b4f148a3b61e89219feec13da2c5cfe6 linux /vmlinuz-linux initrd /intel-ucode.img initrd /initramfs-linux.img options rd.luks.name=29e50f84-592e-4dd7-bba5-5a91132341df=arch root=/dev/mapper/arch rootfstype=ext4 rw rd.luks.name=b385ad32-233d-403b-a1a4-6599d4586f30=mynewpartition
The significant part here is
rd.luks.name=b385ad32-233d-403b-a1a4-6599d4586f30=mynewpartition. This will map
the device with the ID b385ad32-233d-403b-a1a4-6599d4586f30 to
/dev/mapper/mynewpartition. To find the right ID for your partition, you can use
lsblk, eg:
$ lsblk -f NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS sda ├─sda1 vfat FAT32 41EA-BC5D 484M 12% /boot ├─sda2 swap 1 a099ba9d-ab55-4e04-8308-79482bbcdf14 ├─sda3 crypto_LUKS 2 29e5af84-592e-4d03-be85-5811957011df │ └─arch ext4 1.0 da6db103-d6a5-43e8-a19b-a1d280184baa 13.2G 60% / ├─sda4 crypto_LUKS 2 b385ad32-233d-403b-a1a4-6599d4586f30 │ └─test ext4 1.0 e099b20-d45c-44e2-8ea1-31fcfa93ee58 823.2G 42% /f └─sda5 ext4 1.0 08bacd07-b586-415c-b498-7105c41bdf4e
To mount the filesystem on boot, you can then edit /etc/fstab to add an entry
for the partition, which will look something like this:
/dev/mapper/mynewpartition /readonly ext4 discard,ro,nofail 0 2
This will mount the decrypted volume to /readonly. It can be set as readonly just by
providing the ro option.
5. Copying the partition to another disk with pv
Now that my "readonly" partition contains the data I want and automatically decrypts on boot (if I enter the passphrase), I want to backup the data to external disks. I want to do a block-level copy of the encrypted partition as this is simple and gives me some guarantees that the data is the same.
The first step here is to create an appropriate partition on the target disk.
Gparted asks for the desired partition size in Mebibytes (MiB). This means I
need to know the source partition size in MiB. I couldn't find a command
that provided this directly, so had to figure it out using the byte value
returned by blockdev:
$ echo $(($(sudo blockdev --getsize64 /dev/sda7) / 1048576)) 600000
There are various ways to then copy from one device to another. I used pv, as it provides useful feedback on progress:
$ export MY_SOURCE_DEVICE=/dev/sda123 $ export MY_TARGET_DEVICE=/dev/sdb456 $ pv --timer --rate --progress --fineta -s "$(blockdev --getsize64 $MY_SOURCE_DEVICE)" $MY_SOURCE_DEVICE > $MY_TARGET_DEVICE
The -s argument is useful - it tells pv how many bytes to expect, so that it can
display accurate progress information.
Once it's done, you can check that the partitions are the same, and verify that
it worked by opening the new partition with cryptsetup and mounting it again.
6. Backing up LUKS headers
LUKS volumes contain a metadata header. It's useful to backup this header to avoid data loss. Quoting from the cryptsetup manpage:
If the header of a LUKS volume gets damaged, all data is permanently lost unless you have a header-backup. If a key-slot is damaged, it can only be restored from a header-backup or if another active key-slot with known passphrase is undamaged. Damaging the LUKS header is something people manage to do with surprising frequency. This risk is the result of a trade-off between security and safety, as LUKS is designed for fast and secure wiping by just overwriting header and key-slot area.
To support this, cryptsetup provides both a luksHeaderBackup command and a
luksHeaderRestore command.
7. Erasing old disks
I also wanted to securely erase some old disks I had. There are a few ways to do this, but I just looked at two:
Using secure erase
It's possible to issue a Secure Erase ATA instruction to supported devices. This does a firmware-level erase, which can offer advantages over just writing bits to disk (eg. it can be significantly faster, and can erase things that can't be erased by writing to the device, like bad sectors).
You can check whether your device supports secure erase by using hdparm:
$ sudo hdparm -I /dev/sda | grep -i erase
supported: enhanced erase
4min for SECURITY ERASE UNIT. 8min for ENHANCED SECURITY ERASE UNIT.
$ sudo hdparm -I /dev/sdb | grep -i erase
supported: enhanced erase
396min for SECURITY ERASE UNIT. 396min for ENHANCED SECURITY ERASE UNIT.
If your disk does support this, then you can use hdparm to issue the erase in a
couple of commands - see ATA Secure Erase for instructions.
Using pv (or similar)
If your disk doesn't support secure erase, then there are various options that
basically involve writing bytes to the disk using either a dedicated erase tool
like shred, or by coping bytes to the device manually using a tool dd or
cat. For these disks I used pv again as I just wanted to do something simple and
(relatively) fast - eg. I'm not worried about doing multiple iterations.
One choice here is what your source data should be. There are basically two sensible candidates:
/dev/zero: write zeros to the disk. This is often fine, but can supposedly be undone on older disks by amplifying the signal coming from the disk head to differentiate a "zero" that used to store 1 from one that used to store 0./dev/urandom: write random data to the disk. Slower than/dev/zero, but safer if your security model involves protecting against that read amplification attack. I'm curious how much slower this is in practice, but haven't tested it.
8. Monitoring my duplicity backup status
With these changes done I took the opportunity to swap my duplicity backup to a new S3 bucket, to remove any dependency on the old data.
My duplicity script runs on a cron schedule, and essentially just does this:
#!/bin/bash
set -e
echo "$$ | Starting job: $0"
# See man flock for this snippet. It locks so only one version of the script can
# run at once.
[ "${FLOCKER}" != "$0" ] && exec env FLOCKER="$0" flock --verbose -en "$0" "$0" "$@" || :
echo "$$ | Obtained flock"
# Run the backup
duplicity /mysource boto3+s3://mybucket \
--name mybackupname \
--s3-use-ia \
--archive-dir=/myarchivedir \
--exclude-filelist=/mylist.exclude \
--full-if-older-than 365D
# Then some cleanup steps that I'll ignore
# Store the last time the backup finished
date --iso-8601=seconds > /last_success
It would be easy for me to not notice if the backup stopped working, so I display the time of last success in my i3/exwm status bar:
This means the "S3" backup last succeeded 7 minutes ago. The logic for building this string is something like:
if test -f /last_success; then
DUP_S3_DATE=$(cat /last_success)
DUP_S3_SECONDS_AGO=$(( ( $(date +%s) - $(date -d "$DUP_S3_DATE" +%s) )))
DUP_S3_MINUTES_AGO=$(($DUP_S3_SECONDS_AGO / 60))
DUP_S3_HOURS_AGO=$(($DUP_S3_SECONDS_AGO / (60 * 60)))
DUP_S3_DAYS_AGO=$(($DUP_S3_SECONDS_AGO / (24 * 60 * 60)))
if [ $DUP_S3_DAYS_AGO -gt 1 ]; then DUP_S3_MSG="${DUP_S3_DAYS_AGO}d";
elif [ $DUP_S3_HOURS_AGO -gt 1 ]; then DUP_S3_MSG="${DUP_S3_HOURS_AGO}h";
elif [ $DUP_S3_MINUTES_AGO -gt 1 ]; then DUP_S3_MSG="${DUP_S3_MINUTES_AGO}m";
elif [ $DUP_S3_SECONDS_AGO -gt 1 ]; then DUP_S3_MSG="${DUP_S3_SECONDS_AGO}s";
else DUP_S3_MSG="?";
fi
else DUP_S3_MSG="[nofile]";
fi
Thinking about it, it wouldn't be much work to also do an automatic restore to make sure I'm still able to recover, and to display that time too.
9. Backups are hard
My macbook was stolen a few years back, and at the time I was just running one regular backup to S3 - so I had no other copies of my non-cloud data. I hadn't tested restoring this backup from any machine other than the macbook itself, and when I did need to access the data in an emergency it was pretty stressful not knowing if I had all the right credentials accessible and if the restore was going to work. It was a big relief when it did work (thanks Arq).
We're approaching 2022 and I think backups for personal data are still hard to get right, even for technical users. Sure, I make things more complicated by using linux and being more conservative than a lot of people are about sharing private data with cloud services. But I don't think my requirements are too outrageous:
- I have local data which doesn't natively belong to a cloud service, in the order of single-digit TBs.
- I want my data to be protected if I accidentally erase something or if my hardware dies.
- I want my data to be protected in case of house theft or fire - so I need at least one off-site copy.
- I use my laptop on the sofa and other places where it's inconvenient to have an external drive connected via cable.
- For a cloud service, I need to be able to control the encryption myself, or the provider needs to be very reputable so I'm comfortable that they can't access my data.
- I don't want to be locked in to a single cloud service provider.
There's a lot to figure out to achieve this - it's not common knowledge and it's a big enough topic that it can't be self-taught in a quick web search. You have to think about choice of backup software, cost analysis of cloud services, purchasing disks and/or NAS devices, waiting days for the initial backups to run, doing maintenance to confirm that restore process actually works, potentially changing a cloud provider which means another long transfer process, etc.
I can't speak for Windows, but at least on MacOS this doesn't "just work". Time Machine is nice if you have an external disk connected, but I'd have to do some research to figure out how to set it up with a network drive, and then solve the "offsite" backup problem myself separately - and Time Machine isn't even enabled by default (probably as it requires an external drive).
I don't think this problem can be solved without requiring some thought from the user, but it feels like the default behaviour for consumer-facing OSes could be better - because I think most people I know don't go out of their way to back up anything at all. Which can be fine - in practice you can go for many years without losing data, and many people nowadays may not even have much data that doesn't already live in a cloud service. But it sucks if you do lose something important.
I think the closest I've seen to a multi-backend, set-and-forget solution is Arq, which is very nice but sadly doesn't support linux, and still requires some work to figure out your backend configurations. Tarsnap and Backblaze also have their uses - I have memories of very slow upload speeds for Backblaze but I suspect that's better now through some combination of disk/network/software performance.